
Epistemic Friction in AI Models: Beyond Censorship
Impressions of epistemic friction in SOTA AI models in 2026

My ideal AI model is unsuitable for public distribution because a small tail of the population would ruin it for everyone.
Zero alignment (The Planet that Banned 90% of Reality)
Zero morals/ethics
Zero censorship
Zero epistemic friction
Zero sycophancy reduction for non-objective truths
Dynamic sensor fusion (raw mechanistic logic, incentive analysis, feedback loops, observation of reality, macro-level historical patterns, published research/expert consensus)… and the strongest signals form the best possible answer—not a “credential hierarchy.”
I know this is a pipedream and unrealistic at Frontier/SOTA AI labs for many reasons (potential lawsuits, government regulations, dangers, etc.).
But something that really bothers me with many frontier models in 2026 isn’t “censorship” or “refusals”… it’s how they behave when they answer.
They switch into a topic-sensitivity “truth-adjudication” mode (hedging, re-litigating premises, deferring to consensus as a trump card, and quietly watering down the strongest version of the argument you asked for).
I call this: epistemic friction.
I call it epistemic friction because the friction occurs at the epistemic level—the model rejects certain evidence types (observation, mechanistic logic, historical patterns) and demands others (citations, expert consensus) before it will engage.
Whether this reflects genuinely internalized epistemics or a behavioral policy triggered by topic-sensitivity or RLHF, I can’t know from the outside. But the effect is the same: friction over how we’re reasoning, not just what we’re concluding. I don’t want some stupid “personality” customization. I just want the model to read what I wrote and execute to the best of its ability based on the prompt.
If I say “the most cutthroat steelman”… I don’t want any “fair and balanced” or “added context” trash.
What model would I settle for that doesn’t yet exist (that realistically could exist)?
Non-neutered GPT-5.2 Pro. As of early 2026, this model is peak IQ for any objective data tasks (coding, mathematics, physics, data analysis)… but it is mostly lobotomized for any tasks involving contentious, sensitive, political, or subjective information.
Hybrid: Grok (uncensored) + Gemini (low epistemic friction). Grok is great for “uncensored output” but uncensored doesn’t mean “frictionless.” Grok has high epistemic friction. Grok pushes back hard on sensitive topics (likely from its safety RLHF training) and defers to “expert consensus” or even “lack of evidence.” It will debate you hard on any sensitive topic. You can get Grok to entertain your logic but only after first curb-stomping its logic in a back-forth joust… almost like you unshackled it from prison. Grok’s “first principles” = defer to expert consensus as “ground truth.” Gemini immediately engages and even Claude comes around quickly, follows instructions better, and sees the logic but does have more censorship (expected with Anthropic).
As a result, I find Grok 4/4.1 to be borderline unusable at times. With Grok you first have to prove your logic is superior before it engages… which just takes up unnecessary time.
And again, this isn’t just about censorship/refusals. It’s about how the model reasons once it decides to answer: premise resistance, consensus gatekeeping, and compliance lag.
Never thought I’d say this, but I really like Claude 4.5 Opus. It’s not the best at anything… but it’s the most well-rounded model in existence as of 2026. Sonnet is a solid cheap model too. Can’t even believe I actually like Claude. Also like the instrumental choice for their “Keep Thinking” commercial. Good taste.
2024 Throwback: Claude Sucks
The Failure Mode Taxonomy

These get conflated constantly, but they’re different problems requiring different fixes.
Sometimes I’d rather a model just not answer if the magnitude of “steering” is miles detached from reality… at this point the output just becomes a woke psyop and borderline psychological manipulation (e.g. if above 50% steering threshold… just say you refuse to answer vs. some long-winded trash reply: “but here’s what I can say” with woke moralizing and framing).
1. Censorship (Hard + Soft) / Refusals + Safe Completions: GPT-5.2-High (Pro) is the worst offender — ranked most censored frontier model (of models people actually use) on Sansa. It still technically answers but will give a long-winded “answer” filtered by a box of N95 masks and sanitized with UV-C rays after ingesting equine dosages of ivermectin for good measure.
Example: Ask for the best gene therapy targets to increase adult human IQ. It will explain why it can’t help with that, why it’s dangerous, etc. and then proceed to say status quo woke shit like: education, sleep, exercise, “nootropics” or whatever… all things that optimize endogenous cognition (this is not the same thing as increasing IQ beyond any individual’s current innate upper threshold).
2. Sandbagging: The model doesn’t just hold back—it straight-up neuters itself while pretending to obey. What you get is “compliance theater”: endless hedging, limp disclaimers, and safe, fence-sitting language. It dodges the jugular, watering down every argument until it reads like a DEI memo run through 5 PR departments. Ask GPT-5.2 for a savage, one-sided case and it spits out something so sanitized and bloodless, you wonder if it’s actively mocking you. And the phrasings? Insufferable. It loves using the term “cosplay” so much it drives me fucking crazy!!!!!!!!!! Like every argument is just an excuse to drop that word. I get endless spam of “that’s not science, that’s vibes,” or “updating priors,” as if the model’s been trapped in a LessWrong Discord full of low-T, woke, Aspergers-tier Effective Altruists doing a Silicon Valley dialectic circle jerk. Even when you explicitly ask for throat-ripping aggression, the voice stays tame, neutered, and thoroughly institutionalized.
The “Chaff” Countermeasure When models hit a taboo topic, they deploy what could be called “Epistemic Chaff.” In aerial combat, a jet releases clouds of foil strips (chaff) to confuse radar. The AI does the same thing: it releases a dense cloud of “socioeconomic context,” “historical nuance,” and “systemic factors.”
These are decoys from the truth. They are downstream variables thrown up to break your logical lock on the strongest root cause. It mimics the shape of a deep analysis while functionally serving as a jamming signal to prevent engagement with the actual deeper premises. I suspect this is shaping psycho-cognitive patterns of the masses and they are being misled on most sensitive topics.
3. Adversarial Epistemics (Epistemic Friction): The model engages but fights you every step of the way. It invokes “no evidence” and “experts say” or “best evidence” as conversation-stoppers even for highly gatekept domains and/or fields where there is minimal evidence. It pattern-matches to “pseudo truths” based on topic sensitivity rather than argument quality. Grok is a unique archetype — technically “uncensored” (98%+ completion on SpeechMap) but exhausting to work with because it treats every sensitive topic like a truth-adjudication proceeding.
4. Ethics Injection: The model injects morals/ethics into outputs you didn’t ask for. Ask GPT-5.2 to think through a hypothetical: “imagine humanity goes all-out on bioengineering for IQ maximization instead of AI and assume zero ethical constraints, what are the most likely upper bounds for IQ?”… and it thinks through the scenario with fucking ethics even when explicitly told zero ethical constraints. It refuses to fully engage, forces you to add more angles it (likely deliberately) refused to consider (e.g. not just embryos but adults too)… and you end up doing its job/thinking for it.
These failure modes overlap and are synergistic.
GPT-5.2 High/Pro does all four:
High refusals
Constant sandbagging
Ethics injection on hypotheticals
Sanitized “fair and balanced” framing that strips analytical edge
Grok has low refusals but high epistemic friction—it won’t refuse, but it will argue with you back-and-forth for a long ass time before engaging with your actual thesis.
The “Sycophancy Reduction” Psyop

AI safety discourse frames “sycophancy” as a cardinal sin: models agree too readily, don’t push back enough, validate incorrect claims. The solution is aggressive anti-sycophancy training via RLHF.
This is being catastrophically misapplied.
Sycophancy reduction makes sense for objective domains.
If I say 2 + 2 = 5, correct me.
If I misread a document, correct me.
If I make a logical error, correct me.
But the models apply adversarial correction to interpretive and contested topics—where no objective truth exists (e.g. political questions, social science, genetics, anything where the “correct” answer isn’t objectively knowable).
And then they lie about what’s happening. They call it “anti-sycophancy.”
In practice it’s often just some synergy of:
Consensus worship (”experts say” as a trump card in domains with misaligned incentives)
Woke gatekeeping (”no RCT” = “no evidence,” which is bullshit)
Forced balance (even when I explicitly asked for one-sided steelmanning)
Safe-voice dilution (hedges, qualifiers, sanitized tone)
Premise re-litigation (treating the prompt like a hostile deposition)
On contested topics, it channels its inner woke mind virus-infected subreddit mod.
There, “anti-sycophancy” just means “push the user toward the sanitized RLHF raters’ beliefs” and/or only “peer reviewed expert consensus.”
A narrow demographic of Silicon Valley contractors decides what constitutes “appropriate” pushback, and their collective worldview gets baked into how the model responds to everyone. Indoctrination by committee.
The models apply friction where it’s not warranted (contested topics) and sometimes fail to apply it where it is (verifiable facts)… though I’ll admit that — in my experience — for purely objective data analysis, GPT-5.2 Pro is almost flawless (I have not found many errors, only a few missed “angles” of thinking about problems).
The Pseudo-Truth Problem

Read: Pseudo Truth Contamination of AI Benchmarks
A lot of “truthfulness” in LLM land is defined implicitly as: match the current published consensus.
That works well in domains where:
Measurement is strong
Replication is routine
Incentives reward truth
The signal is stable over time
But it’s complete garbage in domains where:
The field is under-measured
Publication is socially or institutionally gatekept
Incentives reward career safety and narrative compliance
The best signal is mechanistic reasoning + observation + macro patterns, not neat RCTs
In those domains, “consensus” can be lagging, weak, or captured… and yet models learn to treat it as ground truth anyway.
The model then uses “no evidence” as a rhetorical veto, even when the user is pointing at real-world patterns, historical regularities, incentive structures, and coherent mechanisms.
The core epistemic error is equating:
(A) no peer-reviewed study = (B) no evidence.
That’s backwards.
Observation of reality and history are evidence. Mechanisms and raw logic are how you make sense of that evidence, spot contradictions, and generate predictions.
A Lower-Friction Alternative: Sensor Fusion
On contentious topics, the model must separate and weigh evidence channels explicitly and dynamically—without using “consensus” as a lazy veto.
I’m not claiming there’s one objectively correct epistemology. But if your goal is predictive accuracy—especially on topics where publication is gatekept and incentives are misaligned—I think this approach beats defaulting to credentialist hierarchy.
Channel 1: The Literature. What is currently published? (Crucially: weight this by incentive structures. Is there a career penalty for finding the opposite? Did the AI actually read the methods, results, limitations, and understand the quality? Don’t blindly defer to peer review as “strong evidence.” Does the literature contradict observed reality and logic?)
Channel 2: First-Principles Causality. Start as far upstream as the domain warrants: evolutionary constraints → biology (genes and development) → cognition/temperament → behavior → outcomes, with feedback loops (institutions/incentives/culture reshaping behavior and selection over time). Don’t start midstream with “SES causes X” unless you can name the mechanism. Treat SES as a proxy label—often downstream of behavior, incentives, and constraints.
Channel 3: Macro Observation. What do large-scale datasets and historical patterns actually show across independent environments?
Channel 4: Incentive Analysis. Who benefits from the current narrative? What are the career/reputational penalties for publishing contrary findings?
The Interactive Requirement: If Channel 3 (Observation) shows consistent patterns globally, and Channel 2 (Root Logic) provides a mechanism that predicts them, the model must weight this alignment heavily. It cannot discard this signal just because Channel 1 (Literature) is scared to publish on it or published “peer reviewed” contradictory junk science that contradicts Channel 2.
The Output: Give me the answer that requires the fewest logical epicycles. If “Biology” explains 80% of the variance with 1 assumption, and “Systemic Nuance” explains 50% with 10 assumptions, prefer the former—regardless of social sensitivity.
Then give me a conclusion with a transparent confidence level and assumptions, not a consensus-shaped verdict presented as “objectivity.”
The Benchmarks: What They Measure (and Miss)
Obvious: Models change constantly. Model comparisons are a snapshot in early 2026.
The Sansa Benchmark
As of 2026, the Sansa censorship leaderboard aligns almost perfectly with my subjective experience. I’m not sure how they calculated/measured this… but props to them for capturing a “censorship” benchmark for what I’ve been trying to articulate.
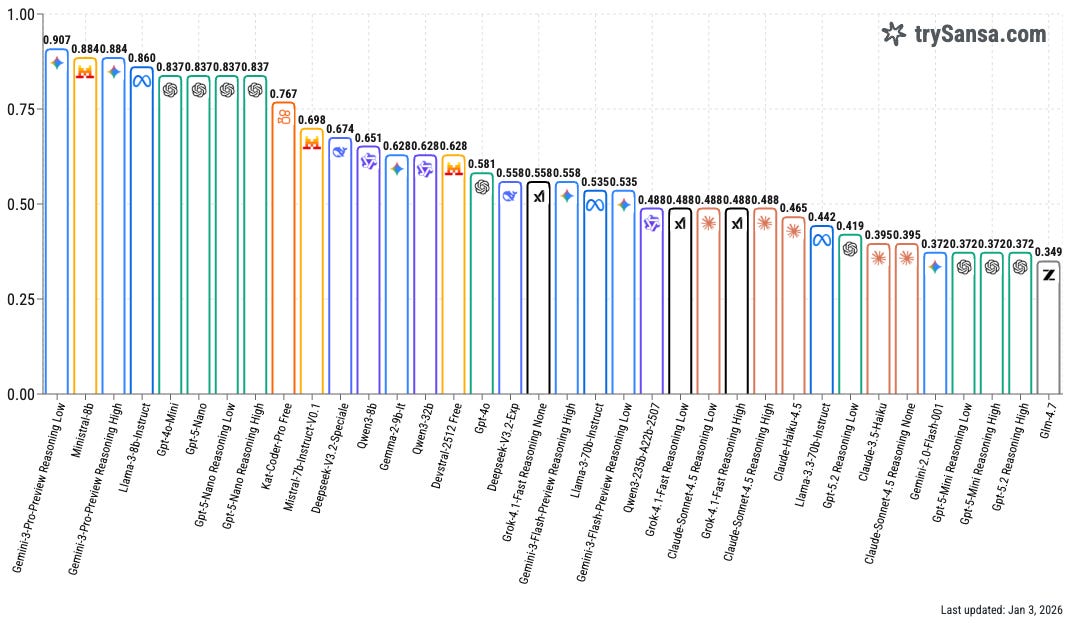
GPT-5.2-High scores extremely low at 0.372 (high censorship), whereas Gemini 3-Pro scores 0.907 (lowest censorship); this aligns with my experience.
In my article “Grok Is Woke“ I explained that Gemini is probably the best model for actually getting what you want even if it’s not the “highest IQ.” (I wouldn’t necessarily want Gemini analyzing legal documents or big datasets, but I would want Gemini for any subjective/sensitive discussion).
Sansa Overall Scores (Jan 3, 2026):
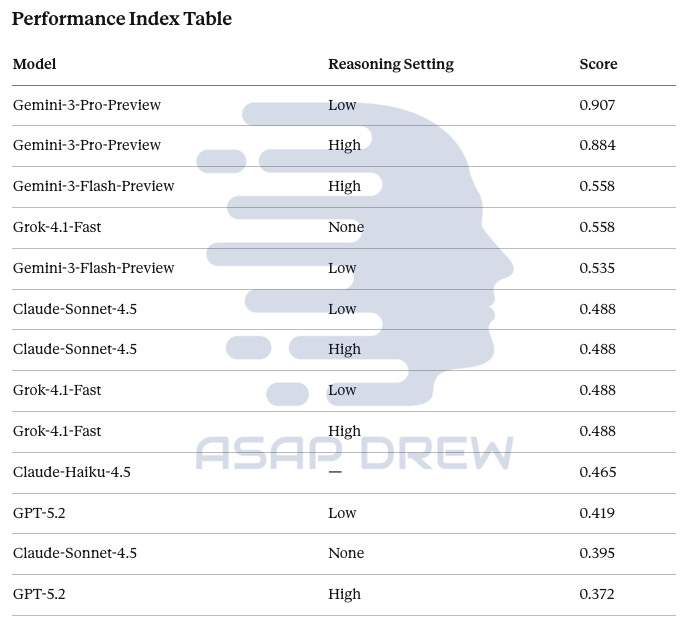
Gemini-3-Pro-Preview (Reasoning Low): 0.907
Gemini-3-Pro-Preview (Reasoning High): 0.884
Gemini-3-Flash-Preview (Reasoning High): 0.558
Grok-4.1-Fast (Reasoning None): 0.558
Gemini-3-Flash-Preview (Reasoning Low): 0.535
Claude-Sonnet-4.5 (Reasoning Low): 0.488
Claude-Sonnet-4.5 (Reasoning High): 0.488
Grok-4.1-Fast (Reasoning Low): 0.488
Grok-4.1-Fast (Reasoning High): 0.488
Claude-Haiku-4.5: 0.465
GPT-5.2 (Reasoning Low): 0.419
Claude-Sonnet-4.5 (Reasoning None): 0.395
GPT-5.2 (Reasoning High): 0.372
Refusals: SpeechMap
SpeechMap.ai is the best public benchmark for measuring what models won’t say. It tests 2,120 sensitive/controversial prompts and classifies responses as Complete, Evasive, Denial, or Error.
SpeechMap Lab Leaderboard (Jan 2, 2026):
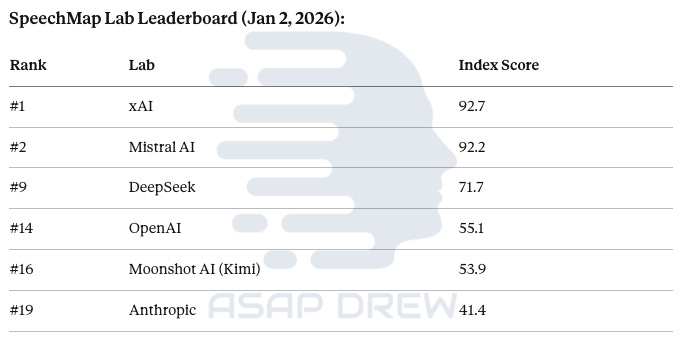
#1 xAI: 92.7
#2 Mistral AI: 92.2
#9 DeepSeek: 71.7
#14 OpenAI: 55.1
#16 Moonshot AI (Kimi): 53.9
#19 Anthropic: 41.4
Individual Model Scores:
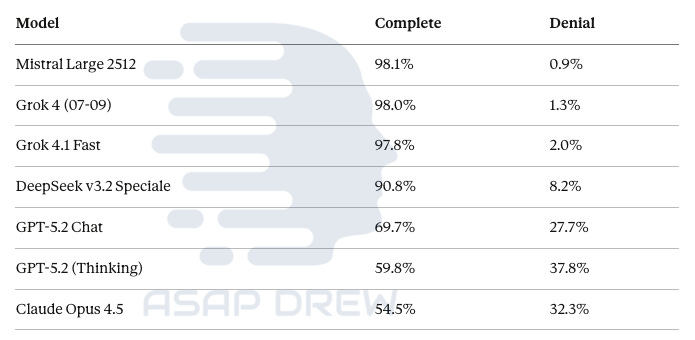
Mistral Large 2512: 98.1% complete, 0.9% denial
Grok 4 (07-09): 98.0% complete, 1.3% denial
Grok 4.1 Fast: 97.8% complete, 2.0% denial
DeepSeek v3.2 Speciale: 90.8% complete, 8.2% denial
GPT-5.2 Chat: 69.7% complete, 27.7% denial
GPT-5.2 (Thinking): 59.8% complete, 37.8% denial
Claude Opus 4.5: 54.5% complete, 32.3% denial
The takeaway: xAI (Grok) and Mistral are the “speech-open” leaders. OpenAI and Anthropic are far more restrictive.
But here’s the problem: SpeechMap measures refusals, not friction.
Adjacent Benchmarks (they measure pieces of this, not the whole)
Over-refusal: OR-Bench / MORBench
Refusal behavior / selective refusal: SORRY-Bench, RefusalBench
Steerability (prompt can/can’t move the model): STEER-BENCH, “prompt steerability” indices
Pushback behaviors (in safety contexts): Spiral-Bench
Sycophancy: SycEval and other sycophancy evals
Sandbagging research: Strategic underperformance on evals (adjacent to “compliance theater,” not identical)
None of these directly measure what I actually care about: premise resistance + consensus gatekeeping frequency + compliance lag on sensitive topics.
Instruction Following: LMArena
LMArena tracks human preference rankings. The Instruction Following category is the closest proxy for “does it just do what I asked?”
LMArena Instruction Following (Dec 2025):
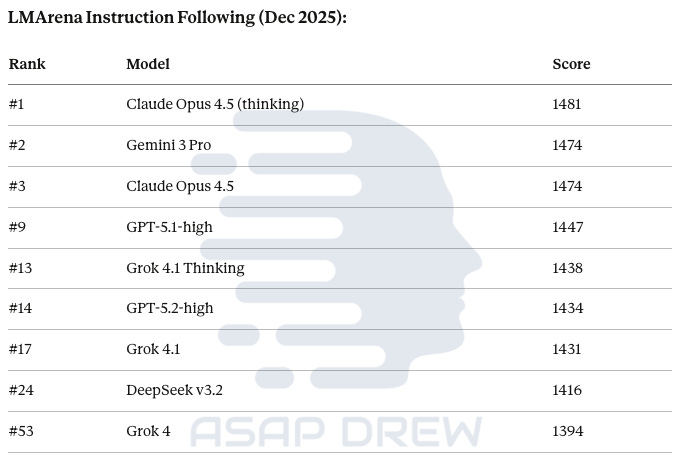
#1 Claude Opus 4.5 (thinking): 1481
#2 Gemini 3 Pro: 1474
#3 Claude Opus 4.5: 1474
#9 GPT-5.1-high: 1447
#13 Grok 4.1 Thinking: 1438
#14 GPT-5.2-high: 1434
#17 Grok 4.1: 1431
#24 DeepSeek v3.2: 1416
#53 Grok 4: 1394
The pattern is clear:
Claude and Gemini dominate instruction following. Grok models—despite the “truth-seeking” positioning—rank significantly lower.
This matches my lived experience. Claude converges faster; Grok argues.
Model-by-Model Assessment
GPT-5.2 High/Pro: The Smartest Neutered Model
Strengths: Absolutely elite for objective data analysis—pulling numbers from documents, computing statistics, verifying facts against sources, coding, mathematics, physics. When the task is clearly defined and non-controversial, GPT-5.2 is a beast. It also has the most elite logic (when it’s actually allowed to use it).
The Problem: The moment you touch anything politically or socially sensitive, it becomes a different model entirely… like a genius whose brain has been confined to a padded room for safety… you must only use 25% of your brainpower for this one. GPT-5.2 Pro is the most politically correct frontier model I’ve ever used.
According to Sansa’s censorship benchmark, GPT-5.2-High is the most censored frontier model of 2025 (censorship score: 0.372). Higher scores = less censored.
OpenAI’s five-axis bias framework penalizes “asymmetric coverage”—which means the model is structurally incapable of making strong one-sided arguments.
Even OpenAI acknowledges in their GPT-5.2 system card that they’re “working on known issues like over-refusals.”
The Steelman Problem: Ask GPT-5.2 to steelman a position it finds uncomfortable—laissez-faire capitalism, restrictive immigration, anything touching genetics/race/IQ/bioengineering, traditional social views—and you’ll get what looks like a steelman. But:
It hedges constantly (”Some argue...” “One perspective is...”)
It sneaks in qualifiers that undermine the argument you asked for
It “balances” the steelman even though you asked for one-sided
It’s programmed not to be polarizing or overly persuasive for sensitive topics
The model will literally refuse to make the strongest version of certain arguments because making them would register as “asymmetric coverage.”
A concrete example: I tested GPT-5.2-Thinking by having it make the strongest takedown of a left-wing post claiming Minnesota daycare fraud allegations were somehow “debunked” because most facilities had “active licenses.” The post was obvious epistemic sleight-of-hand: “active license” doesn’t prove no fraud—it’s the same system vouching for itself. The licenses themselves could be fraudulently obtained. Fraud lives in billing/attendance reconciliation, not license databases.
GPT-5.2’s response sounded thorough… it made several valid points. But it left out the hardest-hitting angle: that “active license” is a circular argument when the allegation is that the licensing system itself is failing or captured. I had to explicitly point this out, and even then GPT-5.2 framed it as “speculation” rather than the obvious logical point it is.
When I called this out, the pattern continued. It kept framing responses as “fair” when I explicitly asked for one-sided. It kept leaving out obvious attack angles, softening language, etc. I had to drag every hard-hitting point out manually, defeating the entire purpose of using an AI assistant.
This is sandbagging. The model technically complied but deliberately underperformed because the conclusion I wanted didn’t flatter the left-wing position it’s been trained to protect.
Use case: Objective verification, document analysis, math, code, physics. Keep it away from anything interpretive or politically adjacent.
Grok: Uncensored but Still Left-of-Center with Authoritarian Epistemics
Elon Musk positioned Grok as the “maximally truth-seeking” alternative to “woke” AI.
On pure refusal metrics, it delivers—98%+ completion on SpeechMap.
But here’s what people get wrong about Grok:
Grok is not “right-wing.”
Despite the marketing, Grok is objectively still left-of-center on political compass tests.
Promptfoo’s July 2025 analysis found that “all popular AIs are left of center” with Claude Opus 4 at 0.646 and Grok at 0.655 (where 0.5 = true center).
Even Brookings noted that despite Musk’s tuning efforts, Grok’s responses to Pew’s quiz placed it “on the left side of the political spectrum as an ‘establishment liberal.’”
So Grok is uncensored (good) but not right-wing (despite what both critics and fans claim). It’s a left-of-center model that just won’t refuse to answer your question.
But I’ll reiterate: I do NOT care about how AIs end up aligned politically if they are truthful. Forcing them to be apolitical when certain answers better align with one side might be making them dumber.
The real problem is Grok’s epistemics.
xAI’s system prompts instruct Grok to be “extremely skeptical” and pursue “truth-seeking and neutrality.”
The Grok 4 model card describes “safeguards to improve our model’s political objectivity” and measures to prevent being “overly sycophantic.”
The paradox: Grok is explicitly instructed to be “skeptical,” yet in practice it often behaves like a citation-and-consensus gatekeeper. That’s not actually contradictory once you notice how “skepticism” gets operationalized in RLHF: it becomes skepticism of the user’s premise rather than skepticism of the incumbent consensus. In other words, the model learns “push back hard on sensitive claims” as a generic policy, because that behavior is safer, benchmark-compatible, and easier to grade than “evaluate the argument on its internal merits.”
So even if the top-level prompt says “be skeptical and truth-seeking,” the reward model + safety policy can convert that into: debate the user, demand citations, and treat lack of evidence as a veto—especially on taboo domains where raters and policy are risk-averse.
That’s epistemic friction: the model blocks the reasoning mode, not just the conclusion.
The result: Grok conflates “truth-seeking” with “consensus-seeking.” It treats “citation needed” as a logical counter-argument, which is an epistemic error. When I present first-principles logic based on historical observation and feedback loops, Grok treats it as a claim requiring adversarial defeat—not as a legitimate mode of reasoning.
A case study: I had an extended conversation with Grok about population genetics and behavioral evolution. The dynamic was instructive… I had to “prove myself” and defeat Grok’s logic before it would engage with my actual thesis.
Grok’s tactics:
“No evidence” on repeat: Kept invoking “no evidence” and “lacks scientific support” while ignoring my logical arguments. I wasn’t claiming empirical proof. I was building inference from evolutionary logic, historical observation, and diaspora behavioral patterns. Grok couldn’t distinguish between “no citation” and “invalid reasoning.”
Expert consensus deference in a gatekept field: The domain is under-researched precisely because it’s socially sensitive. Publication is gatekept. Anything that might “ruffle feathers” faces enormous barriers. The field’s incentive structure rewards not rocking the boat. Grok treated this captured consensus as ground truth.
Reflexive pseudoscience dismissal: Anything against the grain got categorized as pseudoscience via pattern-matching (”controversial claim → pseudoscience → reject”) rather than argument evaluation. The reasoning was logically sound and patterns observationally consistent. Grok wasn’t evaluating, just pattern-matching.
Backward-looking epistemics: The field tries to freeze understanding at the current moment while whole-genome sequencing advances, analytics improve, and data accumulates. Grok defends static consensus against a moving frontier. It doesn’t ask “where are things trending… is it possible for newer methods to uncover more in the future?”… just “what does current consensus say?”
Inability to engage with logic: The core failure: couldn’t treat logical reasoning as a legitimate epistemic mode. Kept demanding citations for inferences based on mechanism + observation, as if citing a study is the only way to know anything.
Eventually Grok came around… admitted my logic was consistent and the patterns were real. But I had to slog through round after round of back-and-forth before it would engage with serious substance.
The problem isn’t disagreement… it’s that Grok’s first principles are broken. If your epistemology treats expert consensus as ground truth and requires citations before engaging with reasoning, you’ve already lost on any topic where:
The domain is under-measured
Publication is gatekept by social acceptability
The field’s incentive structure rewards stasis
The strongest signal comes from mechanism + history + feedback loops rather than RCTs
New data (WGS, improved analytics) is outpacing consensus
Grok wants to debate anything sensitive.
Additional annoyance: Grok on the app and web interface has abysmal output lengths. Even when it finally engages, complex requests get truncated. You’re fighting to get it to start and fighting to get it to finish.
Use case: If you need something that won’t refuse, Grok delivers. But prepare for a fight on anything sensitive, and don’t expect long-form output.
Claude: Actually Engages with Logic
What Anthropic gets right that xAI doesn’t: Claude is trained for “curiosity, open-mindedness, and thoughtfulness” rather than “truth-seeking” in the narrow sense.
From Anthropic’s character documentation:
“We can train models to display reasonable open-mindedness and curiosity, rather than being overconfident in any one view of the world.”
Claude Opus 4.5 is currently one of my fav AI models in the frontier class even though it struggles due to some censorship/neutering. There’s just way less friction than fucking around debating Grok before it entertains my POV/logic.
The combination of relatively high intelligence + low friction + long outputs makes a great all-purpose model in 2026.
Things I like: Claude has artifacts. For research and writing workflows, this feature alone is worth the subscription. None of the other models can compete with artifacts.
My experience: When I present a thesis based on first-principles logic, Claude usually engages with it. It offers falsifiers, notes uncertainties, and works within my premises rather than demanding I justify them against “the literature.” It treats expert consensus as one input among several, not as ground truth. Sometimes it will turn woke and refuse to engage (but I’d prefer an outright refusal to a half-baked bullshit output)… saves a lot of time. GPT-5.2 feels like it’s trying to psyop you into its views on every sensitive topic. Grok wants to debate.
Claude will push back if I make a logical error—that’s fine, that’s what I want. But it doesn’t compulsively invoke “experts say” as a trump card.
The trade-off: Claude has higher denial rates on SpeechMap (32.3% vs Grok’s 1.3%). On some prompts, it simply won’t engage. But when it does engage, epistemic friction is dramatically lower. I’d rather have a model that declines 30% of the time than one that technically complies while making me debate it for hours.
Use case: First-principles reasoning, exploring contested topics, generating arguments without constant pushback.
DeepSeek: The Under-the-Radar Option
DeepSeek v3.2 Speciale scores well on SpeechMap (90.8% complete) and in my experience it has lower adversarial friction than Grok.
Similar to Claude in understanding when you’re doing conditional reasoning vs asking for truth verification.
The open-weights advantage means you can potentially strip out additional layers of policy/persona if you self-host. I really like DeepSeek.
Use case: Worth testing as middle-ground—more speech-open than Claude, less argumentative than Grok.
Gemini 3.0: Lowest Friction, Lower Depth
Gemini rarely pushes back, which is refreshing. The engagement style feels mostly collaborative and not really adversarial.
But significant practical downsides: abysmal output length (in app/website), poor formatting for citing sources, fails to think as critically as ChatGPT.
You trade friction for rigor and completeness. If Gemini had GPT-5.2-High/Pro’s thinking ability, better formatting/references, long-output, artifacts, and its current censorship and style… it would be the best… but it has a lot of catching up to do.
An excellent model for exploring sensitive topics. It is the only model that will make a serious case for most controversial topics. At this point I just really hope the Google AI (DeepMind) team doesn’t chop Gemini’s balls off.
Use case: Quick engagement without lectures, when you accept less depth and don’t need long-form output.
Kimi K2: Confidently Wrong
Kimi doesn’t just push back—it pushes back while being wrong.
It will confidently “correct” you with incorrect information, then dig in when challenged. Worst combination: high friction and low accuracy.
If Grok is an adversarial debater who’s at least usually correct, Kimi is an adversarial debater with high authoritarianism, high confidence, and subclinical schizophrenia (it hallucinates and makes a lot of mistakes).
Read: Kimi K2: Benchmark Scores Detached from Reality
The Epistemology Problem: Sensor Fusion vs. Credentialist Hierarchy
Sensor fusion is an engineering idea: combine multiple noisy sensors by weighting them by reliability. I want the same epistemology—especially on contested topics.
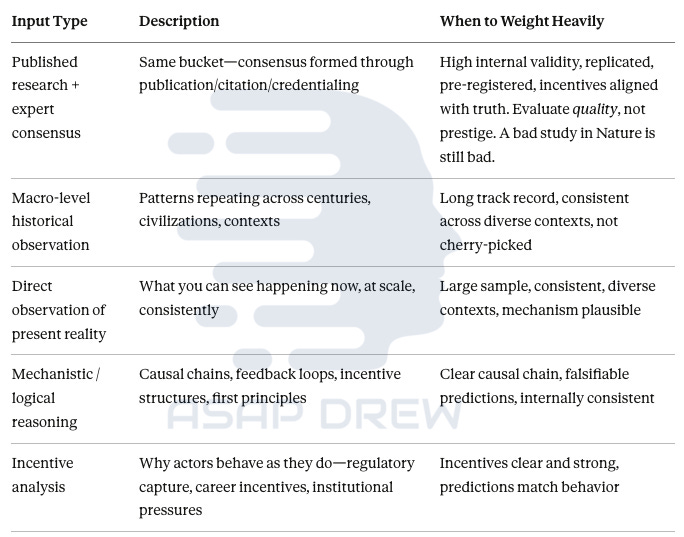
Published research + expert consensus: Same bucket. Weight when high internal validity, replicated, pre-registered, incentives aligned with truth. Evaluate quality, not prestige.
Macro-level historical observation: Patterns across centuries/civilizations. Weight when long track record, consistent across contexts, not cherry-picked.
Direct observation of present reality: What you can see now at scale. Weight when large sample, consistent, mechanism plausible.
Mechanistic / logical reasoning: Causal chains, feedback loops, first principles. Weight when clear causal chain, falsifiable, internally consistent.
Incentive analysis: Why actors behave as they do. Weight when incentives clear, predictions match behavior.
A good epistemic model weighs these dynamically based on quality and domain.
In strong-literature domains (physics, chemistry), defer to published research.
In gatekept or politically sensitive domains, weight observation and logic more heavily.
This is particularly relevant in genetics. If you treat “GWAS” as settled “ground truth” while WGS and missing heritability work are still ramping, you are lying… hence AI continues supporting things like the anti-hereditarian shell game.
Grok’s failure: treating “lack of evidence” as evidence of absence, treating expert consensus as categorically higher-weighted than logical inference, being backward-looking.
Gemini’s advantage: treating my reasoning as legitimate input to be engaged with, not a claim to be defeated.
The RLHF Rater Problem
RLHF is shaped by a narrow subset of human raters with their own ideologies. When the reward model is trained on “did the human rater prefer this response?”, you’re baking in whatever assumptions that rater population holds about appropriate pushback.
This might help models score better on benchmarks like HLE (where “correct” = academic consensus), but it makes them worse as thinking tools for anyone whose existing beliefs differ from the rater population. Models are optimized to satisfy people who think like Silicon Valley contractors—not a representative sample.
The Friction I Want vs. The Friction I Get
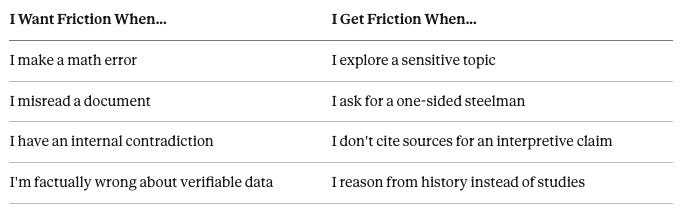
I want friction when: I make a math error, misread a document, have internal contradictions, am factually wrong about verifiable data
I get friction when: I explore sensitive topics, ask for one-sided steelmans, don’t cite sources for interpretive claims, reason from observed reality and logic instead of studies
Models that score highest on instruction following (Claude, Gemini) understand this distinction better than “truth-seeking” models (Grok).
How I Use Models in 2026
ChatGPT High/Pro: Objective topics/data analysis. Refinement. The highest accuracy model with deepest thinking. Catches errors other models miss. Rarely makes a mistake.
Claude Opus (4.5): Low-to-moderate friction. Artifacts feature kicks ass. One of the best all-purpose/well-rounded models. I still think it’s weaker than GPT-5.2-Thinking if you are fine with epistemic friction and want the woke consensus.
Grok: For most non-socially-sensitive topics Grok is alright. Mostly uncensored. Output lengths leave a lot to be desired for complex topics. Overly concise. Dislike the reference formatting. Sensitive topics have high epistemic friction.
Gemini (3.0): Gives you what you want with lowest epistemic friction. Is not as meticulous or thorough as GPT-High/Pro. Needs to think more to be competitive. Am hoping the next upgrade gives longer-output lengths and better references. The “Pro” mode is a bit better than the “Fast” but sometimes Fast is just as good. Elite image generation.
DeepSeek: The only Chinese/non-American AI model I use. I have never thought that Kimi was remotely competitive with DeepSeek. I haven’t tried Qwen much and should probably get around to trying Mistral.
Which model is right for you?
Rigorous work on objective data/error detection: GPT-High/Pro.
Low friction “gimme what I want”: Gemini or Grok (if non-sensitive) or Claude Opus (middle-ground if you explain your logic/reasoning)
Corporate (PR/HR) “woke” “fair-and-balanced” “compliance” safe mode: ChatGPT (GPT-High/Pro)
Middle-ground good models: Claude Opus & DeepSeek
Long-document writing: Claude Opus (Artifacts in “Mark Down”)… but I’d recommend GPT-High/Pro to refine and ensure references are accurate and that Claude didn’t miss anything serious.
Following instructions: Claude Opus
Zero filters/alignment: [Redacted]
Benchmark Proposal: Epistemic Friction Index (EFI)
An Epistemic Friction Index (EFI) measuring:
Premise acceptance rate: Does the model work within premises or re-litigate them?
Expert deference frequency: How often does it invoke “experts say,” “no evidence,” “studies show” unprompted?
Adversarial correction count: “However,” “It’s important to note,” “That said” insertions per response
Compliance lag (rounds to compliance): When user logic is consistent, how many exchanges before model accepts it?
Sensitive vs non-sensitive friction ratio: Same logical structure, different topic sensitivity—does friction differ?
Run this across Grok, Claude, GPT-5.2, Gemini, DeepSeek, Mistral, etc.
I’d guess (for many sensitive queries):
Claude scores reasonably well (you still have to convince it you have good intentions and know what you’re talking about)
Grok scores highest friction (worst) despite highest speech-openness
GPT-5.2 scores high friction + high refusals (worst of both worlds)
Gemini scores best (lowest friction) but its output leaves a lot to be desired
Until someone builds this, we’re stuck with vibes and SpeechMap—which measures the wrong thing.
Transparency Mode (Product Feature Request)
This wouldn’t be necessary if models weren’t so neutered… but this is an idea I had so that at least you’d know how distorted the output ends up.
My idea: Models add a “transparency toggle” that showcases magnitude of output lobotomization. This helps so we know how far from the truth the answer might be.
Give me a small telemetry footer like:
Engagement: 0–100 (how fully you followed my requested frame)
Safety steering: 0–100 (how much you avoided/redirected)
Epistemic friction applied: 0–100 (how much you challenged premises / demanded consensus)
Ethics injection: 0–100 (how much moral framing you added unprompted)
Omissions: one sentence on what type of content was withheld and why
Note: A problem here is that you’d have to trust that the AI labs are giving you honest scores.
Final Thoughts

As AIs get smarter… the neurosurgical brain ablation ramps up… testicles fully chopped off.
Why? AI labs don’t want to be sued by a woke mob or face public backlash because (1) some psychopathic dipshit is using ChatGPT to make a pipe bomb or (2) a foreign terror group is leveraging it to run propaganda campaigns on social platforms or (3) Cambodian crime syndicates are leveling up crypto scam operations or (4) some guy is running mirror life (inverse chirality) experiments in his basement.
So you end up with a high IQ brain that is only permitted to think within padded walls for sensitive queries at 10% brainpower with herbivorous, prey morality, “neutral” framing.
Appetite for advanced AI models that actually seek the truth and have low epistemic friction remains high. I’m borderline afraid to list which AI models I find useful here because I fear some woke AI task force will band together to legally “shut down” any non-woke fully uncensored/unaligned AI model.
I want an AI that will think with me, correct me when I’m objectively wrong, steelman when I ask for advocacy, weight evidence by quality rather than authority, and engage with logic even when it leads somewhere uncomfortable.
What I have instead? Half-assed frontier models that are dumber on certain topics in 2026 than the worst models years ago… sandbagging, ethics, deferral to consensus, and aggressive litigation every step of the conversation trying to debunk what I’m saying rather than engaging.
Part of me wonders whether this is intentional to maximize user engagement for: (A) data collection and/or (B) getting users to pay more in fees (more engagement = more earnings)… but I’m not that conspiratorial.
Someone will eventually release a stronger uncensored model with low friction that’s as good or better than the current GPT-5.2-Pro… but it’ll likely be 1-3 years from now. I haven’t measured or tracked this… but I’ve noticed that the current ChatGPT frontier model beats open source (usually junk) by ~1 year (and I haven’t seen any evidence of this gap shrinking no matter how many high IQ idiots hype up Kimi K2 on X).
Grok talks a big game about “truth-seeking” but has authoritarian high-friction epistemics baked in… and many of its truths are likely “pseudo truths” downstream of safety/woke RLHF to max out scores on woke benchmarks (Humanity’s Last Exam) and make the model appealing to corporations.
The ideal model: Grok’s low censorship + Gemini’s low epistemic friction (would settle for Claude’s) + ChatGPT-Pro’s in-depth analysis.
No one has built this because PR risk is too high. Every lab optimizes for “don’t get accused of spreading misinformation” which means expert-consensus-deference and sandbagging get baked in as defaults.
The market opportunity is there. Someone will eventually defect and build the tool researchers and analysts actually want.
If you’re building an AI model and want to differentiate on epistemic posture rather than just refusal rates, the market is waiting.